요즘 생성형 인공지능 챗봇을 만들어보는 블로그, 문서, 유튜브 등이 너무너무 많아서 이 포스팅은 아마도 누구도 쳐다도보지 않을 것으로 예상되어, 내가 만든 최종 결과물과 함께 자세한 내용을 올려보려고 한다.
개인적으로 Chat GPT나 Claude 등의 생성형 인공지능의 Pro 버전을 구독해서 업무 보조용으로 사용해오고 있으며, 이것들의 덕을 많이 보고 있다. 물론, 아주 길거나 매우 복잡한 형태의 코드는 여전히 한계가 있음을 체감하고 있어서, 함수 하나를 만들거나 하는 매우 구체적이고 매우 좁은 범위의 프로그래밍에 잘 활용해오고 있었다.
난 IT 직종으로서 보통 업무 중에는 문서를 다룰 일이 거의 없는데, 어느 날인가 원천징수 세액을 좀 늘려야할 상황이 생겨서 우리 부서 담당자한테 메일을 보냈다. 그랬더니 링크를 하나 주면서 앞으로는 자기한테 이메일 보내지 말고 여기서 알아서 하면 된다고 했다. 그 이후에 이사를 가게 되어서 주소 변경 신청을 위해 담당자에게 이메일을 보내니, 또 링크를 하나 주더니 거기서 하라고 한다. 이런 일이 여러 번 반복되니까, 누군가에게 이런 걸 좀 부담없이 편하게 물어볼 수 있는 사람이 있었으면 좋겠다는 생각이 들었고, 더 나아가서는 여러 규정집, 법령 등도 구글 검색처럼 키워드 몇 개로 검색해서 문서를 하나하나 들여다보는 검색이 아닌, 사람에게 묻듯 자연어로 검색이 되면 좋겠다는 생각과 동시에, 인공지능을 활용해보면 어떨까 하는 생각이 번뜩였다. 그와 동시에, 학교에서 교수나 직원이 새로 오면 참고하라는 내부 문서를 인트라넷에 보여주는데, 이 문서들이 한두개도 아니고 수백페이지에 가까운데 이걸 누가 보나하는 생각도 들었다. 그래서 이 아이디어를 부서 개발자 미팅할 때 제안을 했고, 아이디어가 괜찮다는 의견을 받아 개발에 시작했다.
인공지능을 쓰는 것에만 관심있던 나에게는 챗봇을 만들기 위한 과정 자체가 상당히 어려웠다. 간단한 웹사이트 개발하는 것 마냥 어디서 잘 굴러가는 스크립트 몇개 줏어다 수정해서 쓸 수 있는 그런 게 아니었다. 더군다나, 인공지능에 관심이 없어보였던 내 사수가, ollama, langchain, pgvector를 언급하는 바람에, 이게 뭔지 알아보기 시작했다. 일단 지금까지 내가 공부해서 알아낸 바는 다음과 같다.
- OpenAI의 유료요금제를 구독하여 GPTs를 통해 앱을 만들면 내가 원하는 형태의 챗봇을 만들 수 있지만, 이 경우는 Chat GPT 구독요금제를 사용하는 유저들만 접근이 가능하다. 따라서, 불특정 다수를 대상으로 하는 서비스는 OpenAI의 API를 사용하여 별도의 앱을 만들어야한다.
- 자기 컴퓨터에서 인공지능을 실행할 수 있다는 프로그램인 ollama를 사용하여, Facebook에서 무료로 공개하는 거대 언어모델인 LLaMA-7b 모델을 m3 맥북프로에서 실행하면 초당 10토큰이 넘는 엄청난 속도로 답변을 해주지만, 이걸 그래픽카드가 없는 Intel Xeon Silver CPU만 장착된 서버에서 실행하면 토큰 하나를 생성하는데 1-3초라는 엄청난 시간이 걸린다.
- 현재의 생성형 인공지능은 문장이나 문단 등을 벡터화(vectorizing)하고, 사용자의 질문도 벡터화하여 이 벡터 데이터를 비교/연산하여 답변이 나오는 형태이다.
- 인공지능을 학습시키는 것과 텍스트를 벡터화하는 것은 다른 작업인데, nVidia A100 같은 한 장에 수천만원짜리 그래픽카드 수천 수만대를 꽂고 이 세상 모든 텍스트를 학습시켜서 나온 결과물을 언어모델이라고 하며, 이 언어모델은 우리가 아는 GPT를 비롯하여 여러가지가 있으며, 특히 Facebook에서 무료로 공개하는 LLaMA라는 언어모델 또한 유명하다.
- 이렇게 학습이 완료된 언어모델과는 별도로 임베딩 모델Embedding Model이라는 것이 있는데, 문서를 벡터화할 때 임베딩 모델을 사용하여 벡터화 해야한다.
- 임베딩 모델에 따라 벡터값이 달라진다. 벡터, 즉 그러니까 행렬의 차원이 높을수록 답변이 정교해진다고 한다.
- 무료로 오픈된 임베딩 모델 또한 https://huggingface.co/models 에 가보면 다양한 모델들이 존재하는데, 처음 테스팅 시 사용했던 all-MiniLM-L6-v2 모델은 384차원이었으며, OpenAI의 text-embedding-3-small은 1536차원이며, 이보다 더 큰 text-embedding-3-large 모델은 3072차원이고, 당연히 요금이 더 비싸다.
- 사용자가 질문을 하면, 이 질문에 대한 검색 체인을 생성하는데, 이 과정에는 언어모델+검색기+대화기록 메모리를 결합하고, 생성된 대화형 검색 체인을 벡터화하여 이 벡터 데이터를 검색 및 연산하여 답변이 만들어진다.
내가 처음부터 생각했던 건, 학교 내 수많은 문서와 규정집 등의 내용에 대해 알려주는 챗봇을 만드는 것이었다. 예를 들면, “학교 VPN에 연결하는 방법을 알려줘”, “학교에서 구입해주는 노트북은 얼마까지 지원해주지?”, “출장 경비는 얼마까지 지원해주지”라는 형태의 질문에 대한 대답을 해주는 식을 상상했었다. 인트라넷에 올라와있는 내부 문서이므로 외부에 공개되면 안되는 문서인데, 그렇다는 건 우리 문서를 Chat GPT 등의 생성형 인공지능에게 학습을 시켜야한다는 의미였다. 그래서, 어떻게 하면 학습을 시킬 수 있는지 알아봤다.
일반적인, 즉 개인적인 용도로는, Chat GPT 유료 구독제에 보면 Assistant라는 기능이 있어서, 여기서 원하는 PDF나 문서 파일을 업로드하면 이 문서에 대한 내용을 주고받을 수 있는데, 테스트 해본바로는 일반적인 목적의 질문과 내가 업로드한 문서의 내용과 혼동하여 답변이 일관적이지 않았는데, 예를 들자면, “내 컴퓨터가 인터넷 접속이 안돼” 라는 질문에서 내가 기대한 답변은 “이러이러한 방법을 시도해보고, 여전히 안된다면 교내 기술지원팀에 문의하세요. 기술지원팀의 연락처와 담당자는 이러이러합니다.”라는 답변이었지만, ChatGPT의 Assistant가 답변한 내용은 그냥 인터넷에서 흔히 나와있는 내용들이었다. 게다가 짧은 답변만 생성됐음에도 불구하고 이유를 알 수 없는 많은 수의 토큰이 생성되었다. 내가 만들려는 챗봇의 목적은 내가 올린 문서들 안에 있는 내용만으로 질문과 답변을 주고받는 게 목적이었지만, 앞서 언급했듯 내가 올린 문서의 내용과 일반적인 내용이 혼동되며, custom instruction을 줬음에도 불구하고 그런 일이 생겼다. 대신, OpenAI의 Assistant에서 생성하는 대답이, OpenAI에서 제공하는 임베딩 모델과 OpenAI와 같은 언어모델을 사용함에도 불구하고, 좀 더 좋아보였다. 그외 일반적인 질문 의 대답은, 생성형 인공지능 API 요금이 마구잡이로 낭비되는 걸 막기위해, 일반적인 질문에 대한 대답을 못하게 막아야했다.
일단, 좋은 성능에 API를 제공하는 거대 생성형 인공지능 서비스를 하고 있는 곳은 OpenAI와 Claude가 있지만, Claude의 API 요금제는 상당히 비싸기 때문에 OpenAI를 사용하기로 했다. 특히 OpenAI에서 최근 새롭게 공개한 GPT 4o 요금이 4 대비 상당히 저렴하기 때문에 정말 부담없이 사용할 수 있는 수준이었다. 그리하여 최종적으로 정리된 챗봇 서비스의 전체적인 개요는 다음과 같다.
- 코로나 이후 학교의 예산 사용이 매우 어려워져서 그래픽카드 구입은 사실상 불가능했다. 따라서 기존에 있는 서버만으로 해결해야한다.
- 학교에서 사용 중인 V-Raptor ARM Arch64 서버 3대에 아래에 설치할 챗봇 관련 스크립트와 패키지를 동일하게 설치하고, 서버 3대 중 한 대에는 PostgreSQL과 nginx를 설치하 여 Round-Robin으로 간단한 로드밸런서를 구성한다.
- 우분투 20.04에서 실행한다.
- OpenAI가 새롭게 공개한 GPT 4o를 사용한다.
- 내부 문서를 모두 벡터화하고, 내부 문서의 유출을 막기 위해 모든 데이터를 학교 내 서버의 데이터베이스에 저장한다.
- 데이터베이스로는 PostgreSQL을 설치하고, PostgreSQL에서 벡터 데이터를 다룰 수 있게 해주는 플러그인 pgvector를 사용한다.
- PostgreSQL의 벡터 데이터 처리 및 벡터 연산 등을 위해 FAISS 플러그인을 사용한다.
- 검색 체인 생성, 질문/답변 생성 등을 한 번에 처리해주는 LangChain을 사용한다.
- 인터페이스로는 현재 챗봇 제작용으로 널리 쓰이는 Streamlit을 사용한다.
- 이렇게 구성하면 최종적으로는 서버에 그래픽카드가 없어도 되는데, 왜냐하면 벡터 연산을 내 서버가 아닌 OpenAI의 서버에서 하기 때문이다.
서버에 PostgreSQL과 pgvector를 비롯한 각종 파이썬 패키지를 설치한다.
apt install postgresql-server postgresql-server-dev
pip3 install pgvector
pip3 install langchain
pip3 install langchain-community
pip3 install langchain-openai
pip3 install openai
pip3 install streamlit
pip3 install pypdf2
pip3 install faiss-cpu
pip3 install psycopg2 # or apt install python3-psycopg2
pip3 install tiktoken
pip3 install st-annotated-text
pip3 install --upgrade plotly설치가 끝났으면 PostgreSQL에 벡터 데이터베이스를 생성해줘야한다. 내가 테스트할 때는 384차원부터 시작해서 1516을 거쳐 3072까지 왔지만, 여기서는 그냥 바로 가장 비싼 text-embedding-3-large 모델인 3072로 설정한다.
CREATE DATABASE vector;
\c vector;
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE documents (id SERIAL PRIMARY KEY, content TEXT, embedding vector(3072));만약 위의 SQL명령어를 실행할 때 권한 관련한 에러가 난다면, chatbot이라는 일반 유저가 벡터 플러그인을 사용할 권한이 없어서 나오는 에러이다. 이 경우를 알아보니 chatbot 유저를 슈퍼유저로 변경하고 테이블을 생성한뒤 다시 일반 유저로 되돌리면 된다고 한다.
ALTER ROLE chatbot superuser;
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE documents (id SERIAL PRIMARY KEY, content TEXT, embedding vector(3072));
ALTER ROLE chatbot nosuperuser;우선, 학교 내부 문서를 벡터화 하는 것이 우선이므로, Google Docs에 올려져있는 인트라넷 내부문서를 PDF로 다운받고, 이 PDF 문서를 벡터화한 뒤 PostgreSQL에 넣는 스크립트를 작성했다. 사실 이 스크립트의 80%는 Claude가 만들어줬다. 아래의 스크립트는 OpenAI의 API 요금제에 금액이 충전되어있어야 사용 가능하다 ($20짜리 개인 구독제랑 다르다).
import os
import openai
import psycopg2
from PyPDF2 import PdfReader
from langchain.vectorstores import FAISS
from pgvector.psycopg2 import register_vector
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
os.environ["OPENAI_API_KEY"] = "api_key"
def get_text_file(file_path):
with open(file_path, 'r', encoding='utf-8') as file:
text = file.read()
return text
def get_pdf_text(pdf_docs):
text = ""
for pdf in pdf_docs:
pdf_reader = PdfReader(pdf)
for page in pdf_reader.pages:
text += page.extract_text()
return text
def get_text_chunks(text):
text_splitter = RecursiveCharacterTextSplitter(
separators="\n",
chunk_size=1000,
chunk_overlap=200,
length_function=len
)
chunks = text_splitter.split_text(text)
return chunks
def get_vectorstore(text_chunks):
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.from_texts(texts=text_chunks, embedding=embeddings)
token_count = sum(len(embeddings.embed_query(chunk)) for chunk in text_chunks)
print(f"\033[32m Total tokens used for embedding: {token_count}\033[0m")
return vectorstore
try:
pdf_files = ['/home/user/chatbot/pdf/COE-Policies-Technology.pdf']
raw_text = get_pdf_text(pdf_files)
print(f"PDF files: {pdf_files}")
#text_file = '/home/user/chatbot/text/text.txt'
#raw_text = get_text_file(text_file)
text_chunks = get_text_chunks(raw_text)
vectorstore = get_vectorstore(text_chunks)
conn = psycopg2.connect(
host="localhost",
database="vector",
user="user",
password="password"
)
register_vector(conn)
cur = conn.cursor()
for i, doc in enumerate(text_chunks):
vector = vectorstore.index.reconstruct(i).tolist()
print(f"{i}: Contents: {doc}")
cur.execute("INSERT INTO documents (content, embedding) VALUES (%s, %s)",
(doc, vector))
conn.commit()
print("Vector data was inserted into the database")
except Exception as e:
print(f"Error: {str(e)}")
finally:
if cur:
cur.close()
if conn:
conn.close()
그리고나서 이 스크립트를 실행하면 아래와 같은 에러메시지를 내뿜지만, 그냥 몇몇 함수가 앞으로는 없어질 예정이라는 warning이므로 무시해도 된다.
/usr/local/lib/python3.8/dist-packages/langchain/vectorstores/__init__.py:35: LangChainDeprecationWarning: Importing vector stores from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:
`from langchain_community.vectorstores import FAISS`.
To install langchain-community run `pip install -U langchain-community`.
warnings.warn(
Text file: /home/user/chatbot/manual.pdf
/usr/local/lib/python3.8/dist-packages/langchain_core/_api/deprecation.py:119: LangChainDeprecationWarning: The class `OpenAIEmbeddings` was deprecated in LangChain 0.0.9 and will be removed in 0.2.0. An updated version of the class exists in the langchain-openai package and should be used instead. To use it run `pip install -U langchain-openai` and import as `from langchain_openai import OpenAIEmbeddings`.
warn_deprecated(
Total tokens used for embedding: 1308672
Vector data was successfully inserted into the database이후 psql에 접속하여 SELECT COUNT(id) FROM documents; 명령어를 실행해보면 데이터가 삽입된 것을 확인할 수 있다.
root@vraptor-04:/home/user# psql -U user -d vector
Password for user user:
psql (12.18 (Ubuntu 12.18-0ubuntu0.20.04.1))
Type "help" for help.
vector=# select count(id) from documents_large;
count
-------
105
(1 row)
vector=# \q
root@vraptor-04:/home/user#이제 웹인터페이스를 만들 차례이다. 요즘 생성형 인공지능 챗봇용 인터페이스로 streamlit이 많이 쓰인다고 위에 언급했는데, 그 이유는 Chat GPT처럼 실시간으로 텍스트가 스트리밍되는 상황에서 이것을 잘 표현해주기 때문인데, 결론적으로 말하자면 streamlit은 내가 만든 것에는 하나도 도움이 되지 않는다. 왜냐하면, ollama 같은 프로그램을 사용하면 streamlit이 도움이 되지만, 내가 만든 것은 벡터연산 및 답변 생성 모두 OpenAI의 서버에서 전부 처리되어 한 번에 나오기 때문에 실시간 텍스트 스트리밍이 아무 의미가 없기 때문이다. 조만간 PHP에 bootstrap 씌워서 다시 만들 예정이지만, 일단 여기서는 원래의 코드를 그대로 올리도록 한다.
또한 아래의 코드는 히스토리를 출력만 해주며, 실제 인공지능이 참조하지 않는다. 왜냐하면, 히스토리를 참조하려면 지금까지 질문/대답했던 내용을 전부 다 올려서 질문에 대한 답변을 생성해야하는데, 이렇게 두면 사용 요금이 기하급수적으로 뛰게되어 장기적인 서비스를 운용한다는 관점에서 좋지못하기 때문이다. 다만, 편의성을 위해 전에 질문했던 내용을 보여주는 정도만 했다.
아래의 스크립트 역시 절반 이상은 Claude가 작성했다.
import os
import json
import openai
import psycopg2
import streamlit as st
from langchain.vectorstores import FAISS
from langchain.chat_models import ChatOpenAI
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferWindowMemory
os.environ["OPENAI_API_KEY"] = "api_key"
@st.cache_resource
def load_data():
conn = psycopg2.connect(
host="localhost",
database="vector",
user="user",
password="password"
)
cur = conn.cursor()
cur.execute("SELECT id, content, embedding FROM documents")
rows = cur.fetchall()
documents = []
for row in rows:
doc_id, content, embedding_str = row
embedding = json.loads(embedding_str)
documents.append((content, embedding))
cur.close()
conn.close()
return documents
def get_vectorstore(documents):
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
vectorstore = FAISS.from_embeddings(documents, embeddings)
return vectorstore
def get_conversation_chain(vectorstore):
memory = ConversationBufferWindowMemory(memory_key='chat_history', return_message=True)
conversation_chain = ConversationalRetrievalChain.from_llm(
llm=ChatOpenAI(temperature=0, model_name='gpt-4o'),
retriever=vectorstore.as_retriever(),
get_chat_history=lambda h: h,
memory=memory
)
return conversation_chain
documents = load_data()
vectorstore = get_vectorstore(documents)
st.session_state.conversation = get_conversation_chain(vectorstore)
st.write("***Documents loaded***:")
if user_query := st.chat_input("Please enter your question"):
print(f"\033[31m Q: {user_query}\033[0m")
if 'conversation' in st.session_state:
if 'chat_history' not in st.session_state:
st.session_state.chat_history = []
result = st.session_state.conversation({
"question": user_query,
"chat_history": st.session_state.chat_history
})
response = result["answer"]
st.session_state.chat_history.append({"role": "user", "content": user_query})
st.session_state.chat_history.append({"role": "assistant", "content": response})
for chat in st.session_state.chat_history[:-2]:
if chat["role"] == "user":
with st.chat_message("Q"):
st.write(chat["content"])
else:
with st.chat_message("A"):
st.write(chat["content"])
with st.chat_message("user"):
st.write(st.session_state.chat_history[-2]["content"])
with st.chat_message("assistant"):
st.write(st.session_state.chat_history[-1]["content"])
스크립트의 실행은 일반적인 python3 ./script.py 형태가 아니라 streamlit으로 해야한다.
root@vraptor-08:/home/user/chatbot# streamlit run ./chatbot.py
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false.
You can now view your Streamlit app in your browser.
Network URL: http://172.19.1.23:8501
External URL: http://127.0.0.1:8501
/usr/local/lib/python3.8/dist-packages/langchain/vectorstores/__init__.py:35: LangChainDeprecationWarning: Importing vector stores from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:
`from langchain_community.vectorstores import FAISS`.
To install langchain-community run `pip install -U langchain-community`.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/langchain/chat_models/__init__.py:31: LangChainDeprecationWarning: Importing chat models from langchain is deprecated. Importing from langchain will no longer be supported as of langchain==0.2.0. Please import from langchain-community instead:
`from langchain_community.chat_models import ChatOpenAI`.
To install langchain-community run `pip install -U langchain-community`.
warnings.warn(
/usr/local/lib/python3.8/dist-packages/langchain/_api/module_import.py:87: LangChainDeprecationWarning: Importing GuardrailsOutputParser from langchain.output_parsers is deprecated. Please replace the import with the following:
from langchain_community.output_parsers.rail_parser import GuardrailsOutputParser
warnings.warn(
/usr/local/lib/python3.8/dist-packages/langchain/_api/module_import.py:87: LangChainDeprecationWarning: Importing get_openai_callback from /usr/local/lib/python3.8/dist-packages/langchain/callbacks/__init__.py is deprecated. Please replace the import with the following:
from langchain_community.callbacks.manager import get_openai_callback
warnings.warn(역시 마찬가지로 많은 에러가 나오지만 위에 언급한 deprecation warning이므로 무시하고, streamlit이 열어놓은 주소와 포트 http://172.19.1.23:8501 로 접속하면 된다.
학교 VPN에 접속하는 방법을 물어봤다.

중요한 정보는 가렸는데 일단 어떻게 하면 되는지 잘 알려주며, 일반적인 질문은 대답을 하지않는다. 질문 2개만 더 보여드린다.
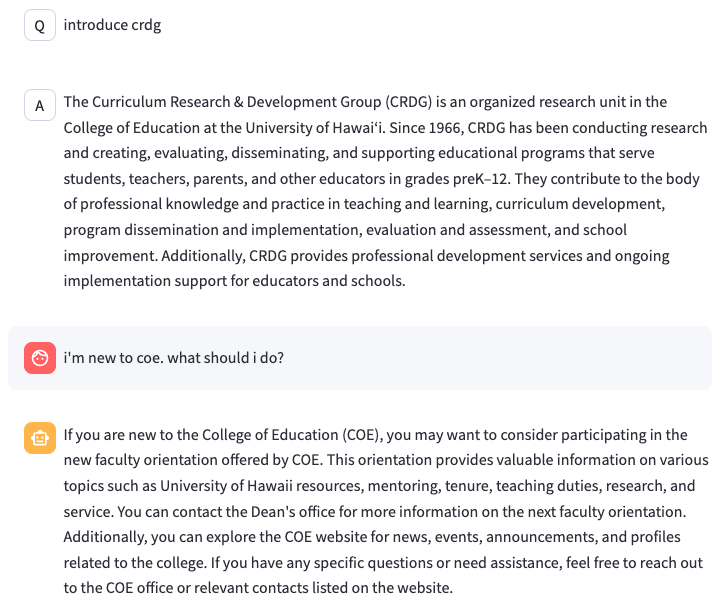
두 번째 질문의 경우 답변이 만족스럽지 않을 수도 있지만, 핵심은 위의 내용은 내부 문서에 없다는 점이다. 교수나 직원이 새로 왔을 때 뭘 해야할지 할 일이 목록 형태로 나열되어 있지만 그걸 정리해서 보여주는 것은 인공지능의 기능에 의해 작성된 답변이므로, 개인적으로는 만족스러운 결과라고 생각한다.
답변 생성시 top 명령어로 프로세스의 CPU 사용률을 보면 20% 정도만 나오는 것을 보아, 모든 벡터 연산은 OpenAI 서버에서 수행되는 것을 확인할 수 있었다. 이렇게, 한정된 예산과 자원으로 원하는 기능을 가진 챗봇을 개발하였는데, 시작은 내가 일하는 곳에서 시작됐지만, 기회가 되어 만약 학교 워크샵에서 발표할 기회가 주어진다면 이 챗봇이 중앙전산실에서 개발하여 학교 전체에 도입 했으면 한다. 왜냐면 일단 나부터도 학교에 퍼져있는 너무나도 많은 문서들을 일일히 다 찾을 수도 없고, 너무나도 많은 규정들을 찾아해맬 수 없기 때문에 이런 유형의 인공지능 챗 봇은 반드시 필요하다.
위의 예제대로 PDF 파일을 사용하여 벡터화해도 인공지능이 잘 이해하지만, 좀 더 정확한 답변을 원한다면, 문서를 인공지능이 더 잘 이해할 수 있게 작성해야한다. 보통 Fine-Tuning이라고 부르는데, 구조화된 문서를 작성하여 체계적이고 일관된 문서를 벡터화하면 인공지능이 더 잘 이해한다고 한다.
내년에 이거 발표하고 상 타는 것 을 이번 목표(희망사항)로 정했다.
넘쳐나는 사규들로 고통받고 있는 입장에서 굉장히 흥미로워 보입니다. 벡터화 시킨 문서들 간 서로 상충되는 내용이 있을 땐 어떻게 답하는지도 궁금하네요. XAI 처럼 챗봇의 답변에 대한 레퍼런스도 확인할 수 있게 관련 규정 PDF 파일도 띄워주는(링크로) 기능도 있으면 재밌을 것 같구요. 혹시 개발에 참고할만한 서적이나 영상 있을까요?
안녕하세요.
제가 작업한 문서들 역시, 문서들 간에 상충되는 내용이 많아서 그것과 관련한 내용에 대한 질문을 하면, 아무리 GPT-4, GPT-4o를 사용하더라도 만족스러운 답변이 나오지 않아서 조사를 좀 해봤습니다. 조사해본 바 결론은 결국, 문서를 잘 써야한다 였습니다. 즉 다시 말하자면, 파인튜닝을 해야한다 이더라구요. 일단 그래서 제가 세운 계획은,
1. 우선 이 시스템을 도입해 사용자들에게 이것이 그들에게 꼭 필요한 서비스가 되게 만들고
2. 부정확한 답변의 경우, 더 나은 답변을 위해 사용자들이 스스로 개선시켜야한다는 생각을 하게 만든다
입니다. 이것을 사용해보고 느끼기 전까진 아무리 개발자들이 파인튜닝을 해아한다 뭘 해야한다 라고 강조해봐야, 일반 유저 입장에서는 자기들이 할 일은 아니라고 생각할테니까요.
규정 PDF 파일을 링크로 띄워주는 기능은 ChatGPT의 Assistant에 아예 기본 기능으로 내장되어 있는데, 이것을 챗봇에 구현하는 건 아직 생각해보지 않았습니다. ChatGPT에서 GPT의 성향을 미리 세팅하는 Custom Instruction 같은 것을 Langchain에서 구현할 수 있는데, 제가 프로그래머가 아니다보니 아직은 시도해보지 못했습니다.
참고한 서적은, 제가 워낙 인공지능 챗봇에 대한 지식이 전무한 상태여서, 기본 지식을 습득하기 위해 책을 하나 구입해서 봤습니다. 책 제목은 “랭체인으로 LLM 기반의 AI 서비스 개발하기” 이구요, 저자는 “서지영” 입니다.
도움이 되셨길 바랍니다.
방문 감사합니다. 좋은 하루 되세요.
참고되었습니다.감사합니다. ^^
안녕하세요 방문 감사합니다.